案例
下面的代码来自我们某一中间件产品源码(Java语言)中(写法一):
// ConcurrentMap<String, AtomicLong> rejectMessageCounts = new ConcurrentHashMap<>();
private AtomicLong getRejectMessageCount(String serviceName) {
AtomicLong rejectMessageCount = rejectMessageCounts.get(serviceName);
if (null == rejectMessageCount) {
rejectMessageCount = new AtomicLong();
AtomicLong currentValue = rejectMessageCounts.putIfAbsent(serviceName, rejectMessageCount);
if ( null != currentValue) {
rejectMessageCount = currentValue;
}
}
return rejectMessageCount;
}
上面的代码是线程安全的,但不够简洁,Java 1.8的ConcurrentMap提供computeIfAbsent()方法,可以简化为(写法二):
private AtomicLong getRejectMessageCount(String serviceName) {
return rejectMessageCounts.computeIfAbsent(serviceName, (key)-> new AtomicLong());
}
回想起曾经走读代码见过如下的写法(写法三,还是以getRejectMessageCount实现为例):
private AtomicLong getRejectMessageCount(String serviceName) {
synchronized(rejectMessageCounts) {
AtomicLong rejectMessageCount = rejectMessageCounts.get(serviceName);
if (rejectMessageCount == null) {
rejectMessageCount = new AtomicLong();
rejectMessageCounts.put(serviceName, rejectMessageCount);
}
return rejectMessageCount;
}
}
但上面的写法也没有线程安全问题,与写法一相比,由于存在synchronized同步锁,范围较大,性能并没有前者好。作者也知道get/put方法是只是原子操作,组合使用则需要synchronized来加锁确保线程安全。
上面案例代码看似简单,但涉及到了线程安全的多个知识点,促使了我写这一篇博文。本文虽是以Java语言呈现,但线程安全的原理是相通的。
背后的知识
ConcurrentMap是JDK1.5开始提供的新接口,用来解决Map操作线程不安全的问题。另一个代替是HashTable,通过synchronized来锁住整个table,无疑在多线程并发又是低效的。ConcurrentMap接口实现者ConcurrentHashMap有两个版本的实现逻辑(JDK1.8以前与1.8),简言之都是划整为零,避免大范围的锁。
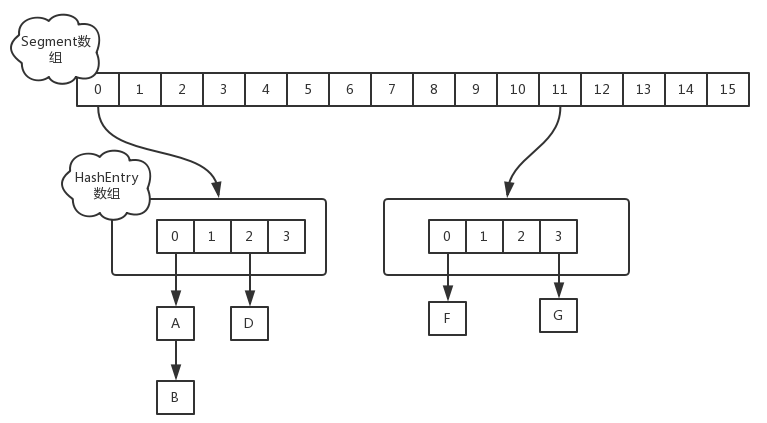
1.8以前版本(为简化说明,后面统一以1.5版本代替)的ConcurrentHashMap采用Segment数组和多个HashEntry来存储数据结构,Segment数组将一个大的table分割成多个小的table来进行加锁。而每一个Segment元素存储的是HashEntry数组+链表,这个和HashMap的数据存储结构一样。
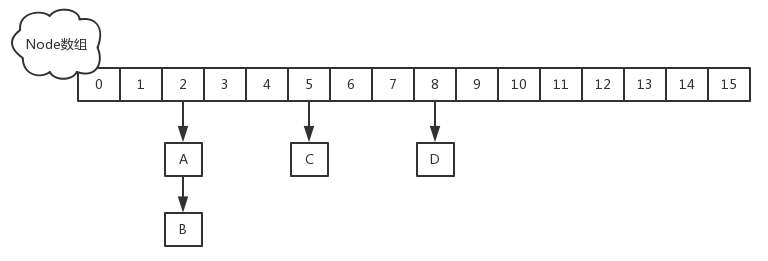
1.8版本的实现已经摒弃了Segment的概念,而是直接用Node数组+链表+红黑树的数据结构来实现,并发控制使用Synchronized和CAS来操作。
以put操作实现为例,对当前的table进行无条件自循环直到put成功,使用了CAS+Synchronized+黑红树:
- 如果没有初始化就先调用initTable方法来进行初始化过程
- 如果没有hash冲突就直接CAS插入
- 如果还在进行扩容操作就先进行扩容
- 如果存在hash冲突,就加锁(Synchronized)来保证线程安全
- 最后一个如果该链表的数量大于阈值8,就要先转换成黑红树的结构
1.5与1.8版本的具体实现细节就不一一展开讲了,有兴趣的同学可以网上搜索相关源码分析。总结区别如下:
- 1.5版本采用ReentrantLock+Segment+HashEntry;1.8版本中synchronized+CAS+HashEntry+红黑树
- 1.8版本的实现降低锁的粒度,1.5版本锁的粒度是基于Segment的,包含多个HashEntry,1.8锁的粒度就是HashEntry(Hash值首节点)
- 1.8版本的数据结构变得更加简单,使得操作也更加清晰流畅,因为基于Hash计算冲突是否加锁,所以不需要分段锁的概念,也就不需要Segment这种数据结构了,由于粒度的降低,实现的复杂度也增加了
- 1.8版本使用红黑树来优化链表,基于长度很长的链表的遍历是一个很漫长的过程,而红黑树的遍历效率是很快的,代替一定阈值的链表
- 1.8版本使用内置锁synchronized来代替重入锁ReentrantLock,synchronized并不比ReentrantLock差,基于JVM的synchronized优化空间更大
回到案例的代码,再来对比说明一下
- 写法三:采用synchronized锁get+put,则锁的范围过大,完全把ConcurrentHashMap中分段/Hash冲突加锁给废了
- 写法一:putIfAbsent方法(底层是putValue)无论1.8版本或它之前的版本,相比synchronized锁get+put进一步降低了锁的粒度
- 写法二:1.8版本针对不存在则put操作场景提供更为简单的API,涉及到线程安全的可见性
线程安全
JDK提供多种容器、原子对象与线程池,让多线程编程变得较为简单,简单后面往往也隐藏复杂性。若对他们不深入了解而使用不当,也会造成多线程安全问题。
多线程编程要确保并发程序正确地执行,必须满足下面三个特性,他们缺一不可:
- 原子性:一个操作或者多个操作 要么全部执行并且执行的过程不会被任何因素打断,要么就都不执行
- 可见性:当多个线程访问同一个变量时,一个线程修改了这个变量的值,其他线程能够立即看得到修改的值
- 顺序性:程序执行的顺序按照代码的先后顺序执行
再回到案例的代码:
- 原子性:由于ConcurrentMap提供的get/put方法是原子操作,他们要么全部能执行,所以
写法三需要加锁来确保 - 可见性:ConcurrentMap的putIfAbsent方法能立即返回其它线程已加入Map中的对象,即拿到最新的值,所以
写法一是没有问题的 - 顺序性:涉及到Java中的指令重排序问题,案例代码不好直接说明此特征,简单说多个线程使用变量依赖是要有序的,不可被打断打乱,volatile变量则不可重排序
锁的优化
线程安全解决办法一般是采用加锁同步,但一旦使用到锁,就会导致多个线程竞争时阻塞。如何让锁的锁定障碍降到最低?
减少锁持有的时间
减少锁持有时间指让锁的的持有时间减少和锁的范围减少,锁的零界点就会降低,其他线程就会很快获取锁,尽可能减少了冲突时间。
减少锁粒度
减小锁粒度指将大对象拆成小对象,大大增加并行度,降低锁竞争。
前面提到的ConcurrentHashMap两种实现,都是为了减少锁粒度,在1.8以前的实现方案中,拆分成多个Segment,写操作时则先定位到某个Segment,只锁定一个Segment。而1.8的实现则更加优化,只有Hash冲突时才会有锁的竞争,Hash不冲突时则采有CAS插入。
锁分离
锁分离就是读写锁分离,JDK中ReadWriteLock维护了一对锁,读锁可允许多个读线程并发使用,写锁是独占的。
ConcurrentHashMap 1.8版本中的存储结构采用黑红树,它也采用锁分离的思路,针对读取的优化,来看一下它的数据结构:
static final class TreeBin<K,V> extends Node<K,V> {
// 指向TreeNode列表和根节点
TreeNode<K,V> root;
volatile TreeNode<K,V> first;
volatile Thread waiter;
volatile int lockState;
// 读写锁状态
static final int WRITER = 1; // 获取写锁的状态
static final int WAITER = 2; // 等待写锁的状态
static final int READER = 4; // 增加数据时读锁的状态
....
当数据操作互不影响,锁就可以分离,例如JDK中LinkedBlockingQueue,当队列中持有数据非一个时,头部和尾部之间的操作是不冲突的,也就可以读写分离,所以可以进行高并发操作。当只一个数据时,才会阻塞操作。
锁粗化
为了保证多线程间的有效并发,会要求每个线程持有锁的时间尽量短。如果对同一个锁不停的进行请求、同步和释放,其本身也会消耗系统宝贵的资源,反而不利于性能的优化。
锁粗化指可以把很多次请求的锁拿到一个锁里面。例如:
for(int i=0;i<MAX;i++){
synchronized(lock){
// 处理逻辑
}
}
则可以优化为:
synchronized(lock){
for(int i=0;i<MAX;i++){
// 处理逻辑
}
}
无锁编程
无锁编程指Lock-free,通常是Wait-free, 即确保线程永远不会阻塞。由于线程永远不会阻塞,所以当同步的细粒度是单一原子写或比较交换时。状态转变是原子性的,以至于在任何点失败都不会恶化数据结构。
无锁有很多种实现,最简单也最普遍的一个通用原语是CAS(Compare and Swap)。JDK提供的AtomicLong等对象,都是采用CAS机制。从命名我们也可以得知,他们的状态转变是原子性。但CAS也有其局限性,感兴趣的同学可以了解一下什么是ABA问题。
volatile变量具有锁的可见性,却不具备原子特性。volatile仅能使用在变量级别,volatile不会造成线程的阻塞。所以可以使用volatile变量来以比同步更低的成本存储共享数据,其使用场景是在多线程读而少线程写的情况。
结语
编写简洁又高效的线程安全代码还是有一定的难度的,我们需要在安全与性能之间平衡。无论Java还是其它语言,都提供了volatile,CAS的Atomic,Lock等不同程度的安全同步原语。JDK提供HashTable,不同版本的ConcurrentHashMap演进,内部的实现细节与其原理太值得我们去深入研究与学习。